

The Importance of Data Redundancy for Ensuring High Availability and Data Integrity
In today’s digital world, data has become one of the most valuable assets for organizations. Its loss can have severe consequences, impacting everything from daily operations to customer satisfaction. To protect this vital resource, businesses need to implement robust data protection strategies. One of the most effective methods to ensure data reliability and availability is data redundancy. This blog explores what data redundancy is, its types, benefits, and best practices for implementation.
What is Data Redundancy?
Data redundancy refers to the practice of storing identical copies of data in multiple locations. It is a strategic approach to data management that goes beyond simple duplication; it incorporates various technologies and infrastructure planning aimed at ensuring data remains accessible, consistent, and protected, even in the event of failure.
Types of Data Redundancy
Data redundancy can take several forms:
-
Hardware Redundancy: Adding additional hardware components so that if one part fails, another can take over, ensuring uninterrupted operations.
-
Software Redundancy: Incorporating additional software to handle failover processes, ensuring the system continues to function even if certain software elements fail.
-
Data Duplication: Storing copies of data across multiple servers or systems, often used to distribute workloads or ensure data is readily available for retrieval.
Benefits of Data Redundancy
Data redundancy offers significant advantages, particularly in improving data availability, protection, and system reliability:
-
Enhanced Availability: Reduces downtime by ensuring continuous access to critical data, even when one system fails.
-
Improved Data Protection: Safeguards against data loss due to issues like hardware failure, cyber-attacks, or human error.
-
Increased Reliability: Ensures the system continues to function smoothly by allowing redundant systems to take over in case of failure.
Effective Strategies for Data Redundancy
Several strategies are available for ensuring redundancy in data systems, each with its strengths depending on the organization’s needs.
-
Backup Solutions: Regular backups of data stored in external drives or cloud storage platforms ensure that a copy of the data is always available if the original is compromised.
-
Clustering: Multiple computers or servers are grouped together as a single logical system. If one cluster element fails, other nodes seamlessly take over, ensuring minimal disruption.
-
RAID (Redundant Array of Independent Disks): RAID configurations, such as RAID 1 (mirroring) and RAID 5 (striping with parity), enhance data reliability by spreading data across multiple drives. RAID levels offer varying degrees of redundancy and performance.
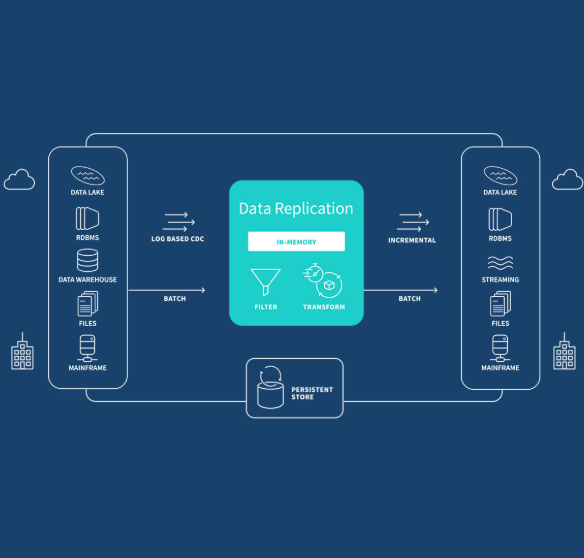
Data Replication
Data replication involves creating exact copies of data and storing them across different servers or locations. This ensures that if one location is compromised, the data can still be accessed from another. There are various methods of data replication, including:
-
Incremental Replication: Updates the replica with only changes made to the original data.
-
Full Replication: Creates an exact copy of the entire dataset.
-
Snapshot Replication: Captures the state of the data at a specific point in time and duplicates it across multiple systems.
Cloud Storage and Data Redundancy
Cloud storage has become a pivotal element in ensuring data redundancy. With cloud services, data can be stored across multiple remote locations, enhancing resilience to local failures. The flexibility and scalability of cloud storage allow organizations to manage data redundancy effectively, ensuring that data remains accessible even in the face of system outages.
Avoiding Wasteful Data Redundancy
While redundancy is crucial for data protection, it’s essential to avoid excessive duplication, which can waste resources and lead to inefficiencies. Businesses need to assess the criticality of their data, determine the appropriate redundancy methods, and avoid over-redundant systems that lead to unnecessary costs.
-
Data Synchronization: Effective synchronization techniques ensure consistency across multiple copies of data. Methods like version control and file synchronization allow for simultaneous updates to various copies, preventing data inconsistency.
-
Cost Management: Redundant data requires additional storage, increasing costs. However, organizations must weigh these costs against the risks of data loss, ensuring they invest in the right level of redundancy for critical data without overburdening their systems.
Best Practices for Data Redundancy Implementation
To implement effective data redundancy, organizations should follow these best practices:
-
Identify Critical Systems: Determine which components of your infrastructure are most important and require redundancy. This could include servers, storage devices, or data centers.
-
Evaluate Redundancy Needs: Assess the level of redundancy each system requires based on its importance to business operations. Some systems may require full redundancy, while others may only need partial backup.
-
Invest in Redundant Infrastructure: Use hardware solutions like dual power supplies, redundant network switches, or RAID storage arrays to ensure systems stay operational even when individual components fail.
-
Design a Redundant Network: Plan your network topology to include redundant paths and connections, ensuring that a failure doesn’t disrupt operations.
-
Implement Monitoring and Failover: Continuously monitor critical systems for failures and deploy failover mechanisms that can automatically switch to backups without manual intervention.
-
Regular Testing: Periodically test the effectiveness of redundancy systems by performing failover drills to ensure that the system operates smoothly during actual failures.
Successful Use Cases of Data Redundancy
Many industries rely on data redundancy to ensure uninterrupted service:
-
Streaming Services: Platforms like Netflix use geographic redundancy to ensure viewers can switch to other data centers seamlessly in case of issues with one data center.
-
Healthcare: Medical systems depend on RAID configurations and off-site backups to keep patient records safe and accessible at all times.
-
Banking: Financial institutions use synchronous data replication to ensure that transactional data is always up-to-date and available, avoiding catastrophic losses.
The Future of Data Redundancy
Looking ahead, the integration of AI into data redundancy management is expected to take center stage. AI will be used for activities like storage provisioning, backup management, and predictive failure analysis. Cloud storage will continue to play a significant role in data redundancy, but we are seeing some organizations bring data back in-house due to cost considerations, compliance requirements, and a need for greater control.
Conclusion
Data redundancy is a vital component of any organization’s data strategy, ensuring the continuous availability and protection of critical data. By implementing the right level of redundancy based on the business’s needs, organizations can safeguard their systems against failure, enhance decision-making, and improve operational efficiency. When done correctly, data redundancy not only prevents data loss but also contributes to the overall resilience and scalability of business operations.


